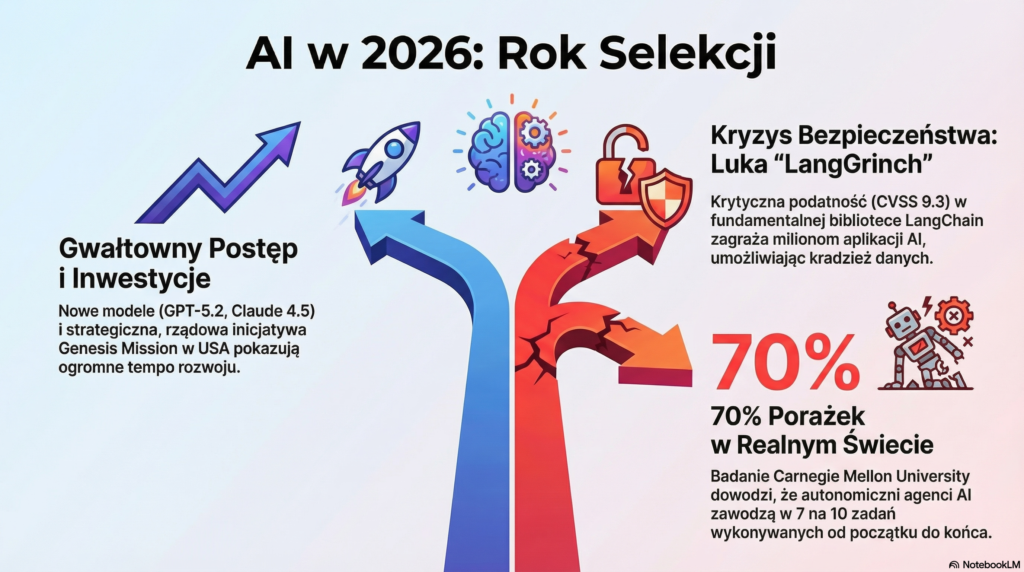
Yarden Porat opisał poważną podatność w bibliotece Lang. Chain[1] (moduł langchain-core), oznaczoną jako CVE-2025-68664 z oceną CVSS 9.3. Luka polega na niebezpiecznej deserializacji: atakujący mogą wstrzykiwać zaufane obiekty przez klucz `lc` w słownikach[2], co umożliwia kradzież tajemnic, tokenów API i poświadczeń chmurowych, a w pewnych konfiguracjach prowadzi do zdalnego wykonania kodu. Badania i raporty firmy Cyata oraz komunikaty społeczności wskazują na konieczność natychmiastowego patchowania[3] bibliotek i aktualizacji do wersji 0.3.81 lub 1.2.5.
Krytyczna luka LangGrinch
OpenAI wypuściła model GPT-5.2 11.12.2025[5], dostępny w trzech wariantach: Instant, Thinking i Pro. Według wewnętrznego memo opisanego przez branżę, pod nazwą „Code Red”, premiera była reakcją na listopadowe postępy konkurencji[4] — zwłaszcza na ogłoszenie Gemini 3 — i na słowa Sam Altman, który zadeklarował „wyjdziemy z Code Red do stycznia”. GPT-5.2 ma celować w zastosowania profesjonalne; firma udostępniła model użytkownikom ChatGPT Pro i przez API, nie ujawniając szczegółowych stawek.
Wyścig modeli i benchmarki
Anthropic ogłosiła w listopadzie 2025 wydanie Claude Opus 4.5[7], które firma promuje jako model optymalny dla agentów i programowania. W praktyce rynek LLM stał się bardziej zróżnicowany: xAI oferuje Grok 4 i Grok 4 Heavy w planach płatnych ($30/mies. oraz $300/mies.), a Deep. Seek rozwija V3.1 z hybrydowym rozumowaniem[16]. Ta fragmentacja zmienia kryteria wyboru dla przedsiębiorstw: nie wystarczy „najlepszy ogólnie”, liczy się dopasowanie do zadań.
Problemy z oceną agentów narastają. Badacze opublikowani przez Clément Schneider i zespół D. Kang wskazali[14], że wiele benchmarków dla agentów zawiera błędy metodologiczne i skróty ewaluacyjne. Równocześnie Carnegie Mellon University opublikowała analizę, z której wynika[15], że agenci zawodzą około 70% przypadków w scenariuszach end-to-end; ludzie zawodzą w 30%, a systemy hybrydowe człowiek+AI w około 15%. Te dane podważają zaufanie do benchmarków i zwiększają wartość narzędzi governance.
Genesis Mission i konsekwencje
Google Deep. Mind ogłosiła 17.12.2025 partnerstwo z U. S. Department of Energy[11], w ramach programu Genesis Mission: wszystkie 17 narodowych laboratoriów DoE uzyskały dostęp do agentów naukowych[10] opartych na Gemini oraz do platformy Gemini for Government. Administracja White House postrzega projekt jako sposób na skrócenie cyklu badań z lat do dni; planowane są moduły Alpha. Evolve (kodowanie), Alpha. Genome (DNA) i Weather. Next (prognozy pogodowe). Rządowe wdrożenie frontier AI ma charakter precedensowy i może przyspieszyć badania, ale budzi też pytania o nadzór i ryzyko.
Wpływ rynkowy i regulacyjny jest wyraźny. European Commission przesunęła 19.11.2025 obowiązki dla systemów wysokiego ryzyka[20], łagodząc zasady anonimizacji i uproszczając reguły cookies, co ma zwiększyć konkurencyjność UE. Na rynku powstają standardy techniczne: Linux Foundation stworzyła Agentic AI Foundation[6] i promuje Anthropic Model Context Protocol (MCP) jako sposób na interoperacyjność agentów. W międzyczasie Service. Now przejęła Veza (transakcja szacowana na $2.7B)[22], a firmy bezpieczeństwa, takie jak Rubrik, odnotowują wzrost popytu na narzędzia audytu AI. Wnioski są jasne: 2026 będzie rokiem selekcji — przetrwają systemy z solidnym governance, audytem i bezpieczeństwem.
Źródła
Powiązane wpisy:
- Agenci AI wchodzą do biur, rośnie fala ataków i presja AI Act
- Tygodniowy przegląd AI: dominacja Gemini 3 Pro, megafunding dla xAI i nowe regulacje w Kalifornii
- Kapitał, agenci i regulacje: tydzień przełomu w globalnym wyścigu AI
- Tydzień przełomu w AI: chińska ofensywa, agentowe platformy i kryzys bezpieczeństwa